38 variational autoencoder for deep learning of images labels and captions
Data Sets for Deep Learning - MATLAB & Simulink - MathWorks Discover data sets for various deep learning tasks. Skip to content. ... which are used in the example Train Variational Autoencoder (VAE) to Generate Images. ... The data set is useful for training networks that perform semantic segmentation of images and provides pixel-level labels for … Plant diseases and pests detection based on deep learning: a … Feb 24, 2021 · Pu Y, Gan Z, Henao R, et al. Variational autoencoder for deep learning of images, labels and captions [EB/OL]. 2016–09–28. arxiv:1609.08976. Oppenheim D, Shani G, Erlich O, Tsror L. Using deep learning for image-based potato tuber disease detection. Phytopathology. 2018;109(6):1083–7. Article Google Scholar
Yangzhangcst/Transformer-in-Computer-Vision - GitHub 2 days ago · (arXiv 2022.02) AI can evolve without labels: self-evolving vision transformer for chest X-ray diagnosis through knowledge distillation, (arXiv 2022.02) ScoreNet: Learning Non-Uniform Attention and Augmentation for Transformer …

Variational autoencoder for deep learning of images labels and captions
plantmethods.biomedcentral.com › articles › 10Plant diseases and pests detection based on deep learning: a ... Feb 24, 2021 · Pu Y, Gan Z, Henao R, et al. Variational autoencoder for deep learning of images, labels and captions [EB/OL]. 2016–09–28. arxiv:1609.08976. Oppenheim D, Shani G, Erlich O, Tsror L. Using deep learning for image-based potato tuber disease detection. Phytopathology. 2018;109(6):1083–7. Article Google Scholar A Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · A stacked autoencoder (SAE) is a typical deep learning model of the encoder-decoder architecture (Michael ... component is introduced to adaptively combine input and states. Jang, Seo, and Kang designed the semantic variational recurrent autoencoder to model the global text features in a sentence ... To generate captions for images, ... Image classification | TensorFlow Core Aug 12, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance
Variational autoencoder for deep learning of images labels and captions. IEEE ICASSP 2022 || Singapore || 7-13 May 2022 Virtual; 22-27 May … A Bayesian Permutation training deep representation learning method for speech enhancement with variational autoencoder: 8962: A BENCHMARK OF STATE-OF-THE-ART SOUND EVENT DETECTION SYSTEMS EVALUATED ON SYNTHETIC SOUNDSCAPES: 3369: A BERT based Joint Learning Model with Feature Gated Mechanism for Spoken Language Understanding: … › help › deeplearningData Sets for Deep Learning - MATLAB & Simulink - MathWorks Discover data sets for various deep learning tasks. ... Train Variational Autoencoder ... segmentation of images and provides pixel-level labels for 32 ... aclanthology.org › events › naacl-2022North American Chapter of the Association for Computational ... In the study, we propose a novel learning method for learning how to attend, called LEA, through which meta-level attention aspects are derived based on our meta-learning strategy. This enables the generation of task-specific document embedding with leveraging pre-trained language models even though a few labeled data instances are given. DeepTCR is a deep learning framework for revealing sequence ... - Nature Mar 11, 2021 · A variational autoencoder provides superior antigen-specific clustering ... Y. et al. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 29 ...
github.com › 52CV › CVPR-2021-PapersGitHub - 52CV/CVPR-2021-Papers Multi-institutional Collaborations for Improving Deep Learning-based Magnetic Resonance Image Reconstruction Using Federated Learning ⭐ code 多机构合作,利用联合学习改进基于深度学习的磁共振图像重建技术; DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images North American Chapter of the Association for Computational … In the study, we propose a novel learning method for learning how to attend, called LEA, through which meta-level attention aspects are derived based on our meta-learning strategy. This enables the generation of task-specific document embedding with leveraging pre-trained language models even though a few labeled data instances are given. aclanthology.org › events › acl-2021Annual Meeting of the Association for Computational ... Inspired by the strong exploration ability of the deep Q-learning network (DQN), we propose a DQN-based approach to retrieval of precise evidences. In addition, to tackle the label bias on Q-values computed by DQN, we design a post-processing strategy which seeks best thresholds for determining the true labels of computed evidences. Annual Meeting of the Association for Computational Linguistics … Inspired by the strong exploration ability of the deep Q-learning network (DQN), we propose a DQN-based approach to retrieval of precise evidences. In addition, to tackle the label bias on Q-values computed by DQN, we design a post-processing strategy which seeks best thresholds for determining the true labels of computed evidences.
› articles › s41467/021/21879-wDeepTCR is a deep learning framework for revealing sequence ... Mar 11, 2021 · A variational autoencoder provides superior antigen-specific clustering ... Y. et al. Variational autoencoder for deep learning of images, labels and captions. Adv. Neural Inf. Process. Syst. 29 ... Accepted Papers – TheWebConf 2022 Apr 29, 2022 · Search. A Category-aware Multi-interest Model for Personalized Product Search Jiongnan Liu, Zhicheng Dou, Qiannan Zhu and Ji-Rong Wen; A Gain-Tuning Dynamic Negative Sampler for Recommendation Qiannan Zhu, Haobo Zhang, Qing He and Zhicheng Dou; A Model-Agnostic Causal Learning Framework for Recommendation using Search Data Zihua Si, … direct.mit.edu › neco › articleA Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · Abstract. With the wide deployments of heterogeneous networks, huge amounts of data with characteristics of high volume, high variety, high velocity, and high veracity are generated. These data, referred to multimodal big data, contain abundant intermodality and cross-modality information and pose vast challenges on traditional data fusion methods. In this review, we present some pioneering ... Image classification | TensorFlow Core Aug 12, 2022 · This is a batch of 32 images of shape 180x180x3 (the last dimension refers to color channels RGB). The label_batch is a tensor of the shape (32,), these are corresponding labels to the 32 images. You can call .numpy() on the image_batch and labels_batch tensors to convert them to a numpy.ndarray. Configure the dataset for performance
A plot of contrast-to-noise (a) and signal-to-noise (b) ratios compare... | Download Scientific ...
A Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · A stacked autoencoder (SAE) is a typical deep learning model of the encoder-decoder architecture (Michael ... component is introduced to adaptively combine input and states. Jang, Seo, and Kang designed the semantic variational recurrent autoencoder to model the global text features in a sentence ... To generate captions for images, ...

YUNCHEN PU | Duke University, North Carolina | DU
plantmethods.biomedcentral.com › articles › 10Plant diseases and pests detection based on deep learning: a ... Feb 24, 2021 · Pu Y, Gan Z, Henao R, et al. Variational autoencoder for deep learning of images, labels and captions [EB/OL]. 2016–09–28. arxiv:1609.08976. Oppenheim D, Shani G, Erlich O, Tsror L. Using deep learning for image-based potato tuber disease detection. Phytopathology. 2018;109(6):1083–7. Article Google Scholar

Yunchen PU | Duke University, North Carolina | DU

a) Magnetic anomaly map of the model in Figure 2. b) Signum transform... | Download Scientific ...
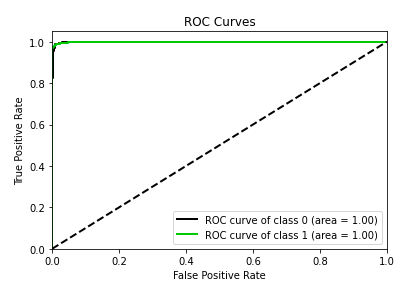
FaceMask Detection | Home
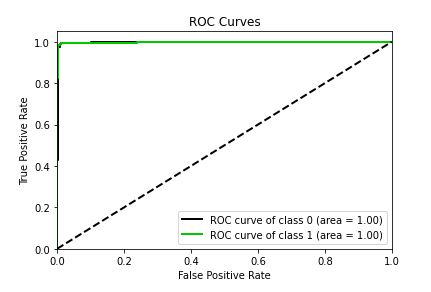
FaceMask Detection | Home
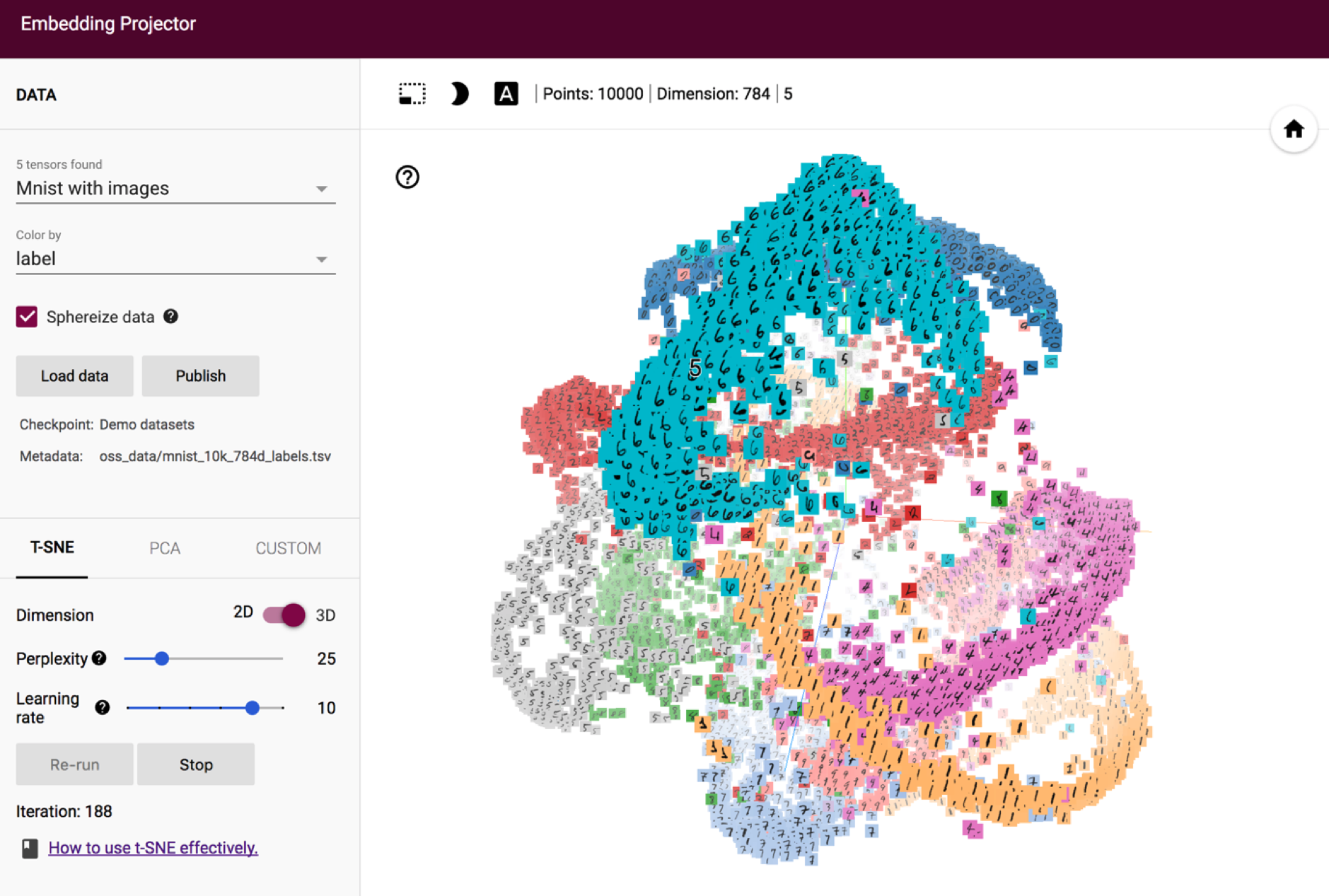
Unsupervised deep learning models used in computer vision — Steemit

Semi-supervised classification accuracy on the validation set of... | Download Scientific Diagram
Post a Comment for "38 variational autoencoder for deep learning of images labels and captions"